
My first professional software development job was writing diagnostic software for the K7 processor at AMD. What an incredible place and time for a college student. All these complex pieces fit together to build a working computer: software, CPU, northbridge, southbridge, RAM, PCI cards. When it all worked, the system could do amazing things. When one of those pieces had a tiny bug, the whole system fell apart.
I've been working at the intersection of hardware and software ever since — most recently with iOS apps and Bluetooth Low Energy (BLE) peripherals. The systems are smaller now, but the integration challenges are the same. Maybe worse, because now you're also coordinating wireless protocols, battery constraints, and a mobile OS you don't control.
What follows is what I've learned about keeping these projects on track.
What BLE System Integration Actually Requires
BLE system integration isn't just pairing a phone with a peripheral. I've seen teams treat it that way — write some CoreBluetooth code, flash the firmware, and wonder why things fall apart at the demo. The reality is that you're coordinating at least four layers: firmware running on constrained hardware, an iOS (or Android) app managing a state machine you don't fully control, a cloud backend that needs to make sense of what the device is reporting, and a user who expects all of it to feel like one product.
Each layer has its own failure modes, its own timing constraints, and its own team that thinks their part works fine. There is no single "hard part." The difficulty springs at the joints and seams between layers and systems. An iOS app that accidentally consolidates two separate updates. A characteristic write that the firmware misses because it expected a different order of operations. A bug fix that destroys system performance.
I've shipped products across all of these failure modes. The guide that follows is what I've learned about keeping those seams tight — through continuous integration, disciplined controls, and the habit of testing the real system early and often.
A Note on "Best Practices"
If you're an engineer, you're probably annoyed at the term "best practices." How the heck would I know what the best practices are? I don't. For all I know, Apple could have flying drones hovering over the shoulders of all their engineers, politely offering suggestions as they write code at their unbelievably neat desks. That would be better than any practices I've seen.
Perhaps a Google AI writes all their BLE code. Who knows the "best practices" and which organization has them? I'm simply sharing a few tactics and strategies I've used to help keep projects on track. They work for me and the many projects I've worked on over the decades. They will work for you and your team too.
ABI — Always Be Integrating
A = Always. B = Be. I = Integrating. That's my mantra, my big hardware/software strategy. It's a little like releasing a minimum viable product, except it is about your system rather than product/market fit. As Gall's law claims, complex systems that work evolve from simple working systems.
Integrating helps you learn how your system works and where it might fail while the system is still simple enough to debug easily.
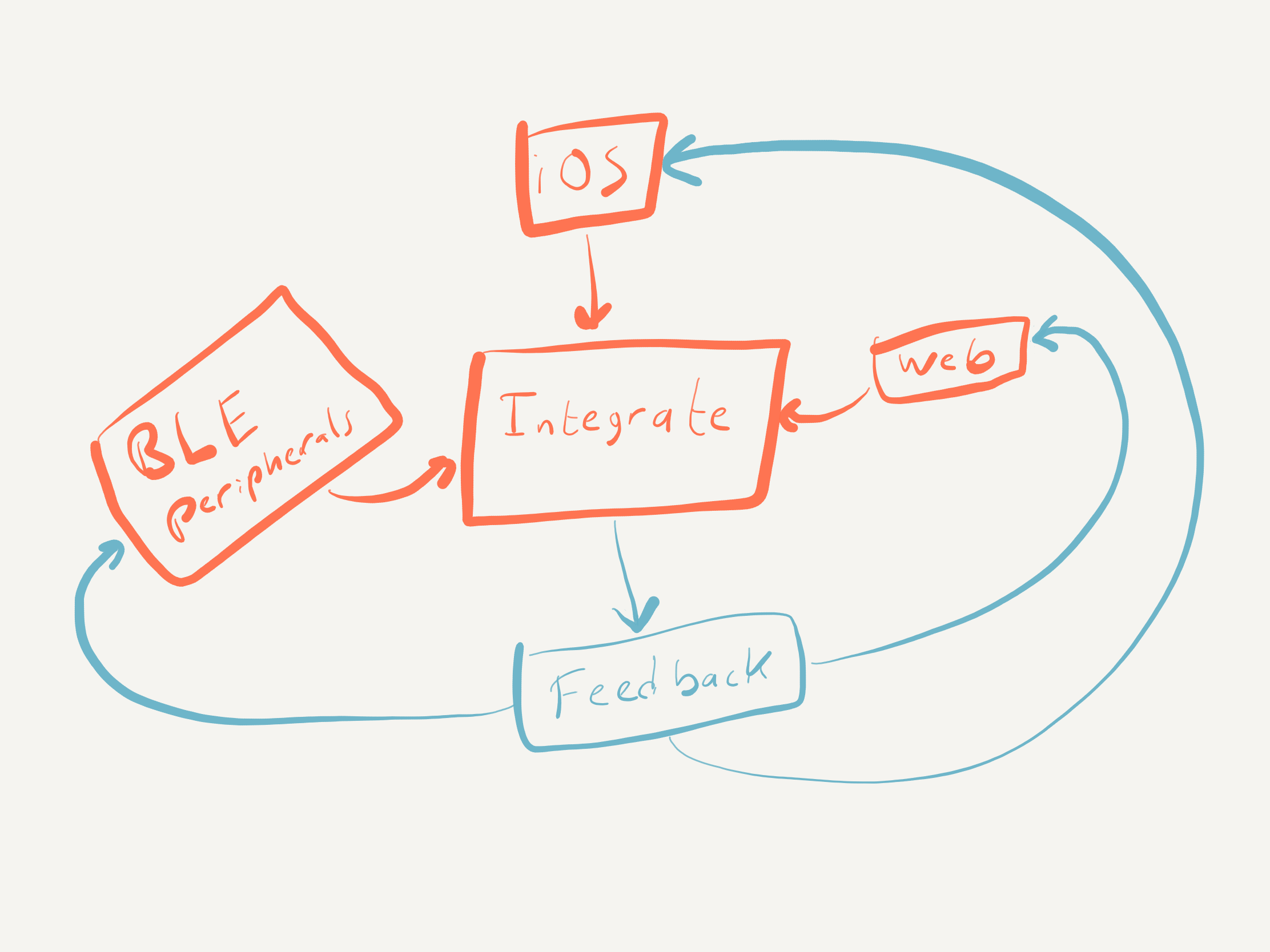
Early integration also finds design problems while they're still cheap to fix. On one project, early integration caught an issue with the peripheral hardware. It passed every directed test we threw at it but reliably failed when used with our iOS app for more than a few minutes. We had to change the hardware design and peripheral firmware to use a different module.
If I hadn't pushed for early integration testing and lobbied to make investigating that problem first priority, we would have spent millions building firmware and final hardware on a shaky foundation. That kind of rework can kill a product.
Here are two anti-patterns I've seen play out on teams that skip continuous integration.
Development in Isolation
A few large organizations I've worked with had a siloed approach to products. One group builds module X. Another group works on the same product but only on module Y. The group leaders have regular meetings to monitor progress:
"How's the firmware going?"
"Oh, it's excellent! How's the software?"
"Oh, perfect!"
As far as anyone knows, they're executing the project plan flawlessly. Each team has conducted directed tests to bolster their confidence. Without feedback from integration testing, the project appears on track.
Then integration day arrives. It always reveals surprises. Leaders who lack hardware experience feel like their team fooled them.
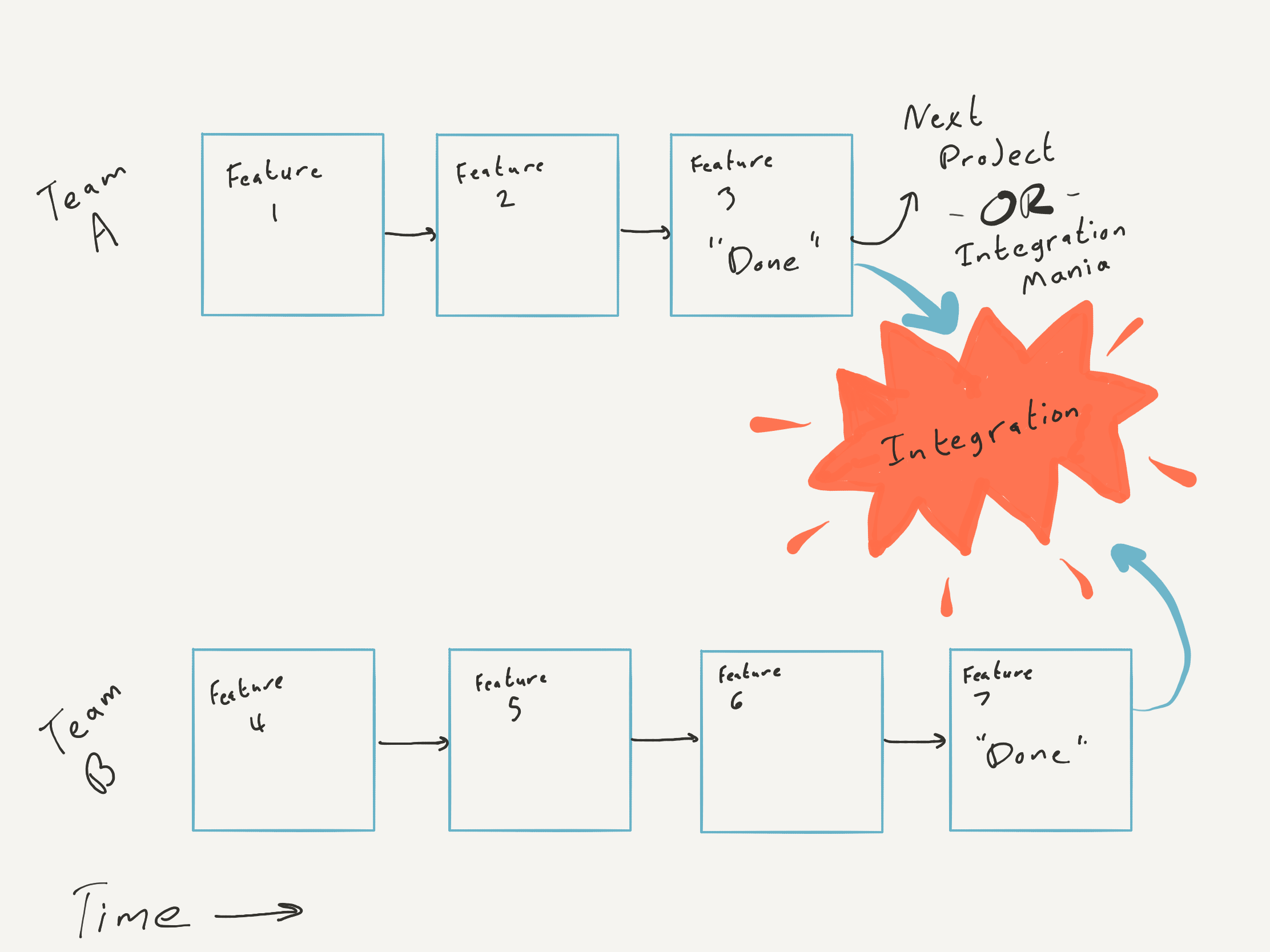
"How did this happen? Last week, everything looked beautiful. Today we're scrambling to figure out why the app is crashing, and the firmware drops the BLE connection every five minutes!"
This "integration wall" seems predictable to engineers with hardware experience but holds a genuine surprise for folks with a traditional software background. Project managers can spend entire careers on products where engineering hedges integration risks with common frameworks and abundant computing power. BLE products face uncommon risks — battery life, limited computing power, low-level bit-bashing — and those risks compound when you defer discovery to the end.
A siloed approach creates the illusion of fast progress while deferring the discovery of bugs, unknowns, and flawed assumptions to the project's final phase. The later stages of a software project are when bugs cost the most to fix.
The Rotten Egg
The last team to finish gets stuck with all the integration work.
This trap springs when one side finishes and moves on to its next project before integration testing completes. The "rotten egg" team starts integration and faces an uphill battle to get help from teams who've already moved on. One group ends up implementing one-sided workarounds or taking on technical debt just to ship.
Don't get caught by this dirty trick; the team still working on their part of the project might have been left a mess by another team.
The Cure — Test the Real System Early
Unit tests, simulators, shared test pattern libraries — all great. But physical reality is the best simulator. The real world is always 100% accurate.
Think about a spider web. The spider doesn't cut hundreds of bits of silk to length and then assemble it on a tree. Instead, it runs strands from one branch to another, one at a time. Each strand has the correct length because the spider builds it on the tree — no need for calibrated rulers or theodolites. Reality is the best test.
Or imagine building a railroad with two teams laying track, intending to meet in the middle. You can use GPS, maps, and surveys to ensure the rails line up. But the simplest approach is to look up from time to time and check that your tracks seem to converge.
Is it precise? No. But if the two sections of track obviously won't meet, nobody can dispute it. The same goes for systems. If your iPhone app and Bluetooth dongle can't talk to each other, it hardly matters what unit tests are passing or how many Jiras you moved to the end of the swim lane.
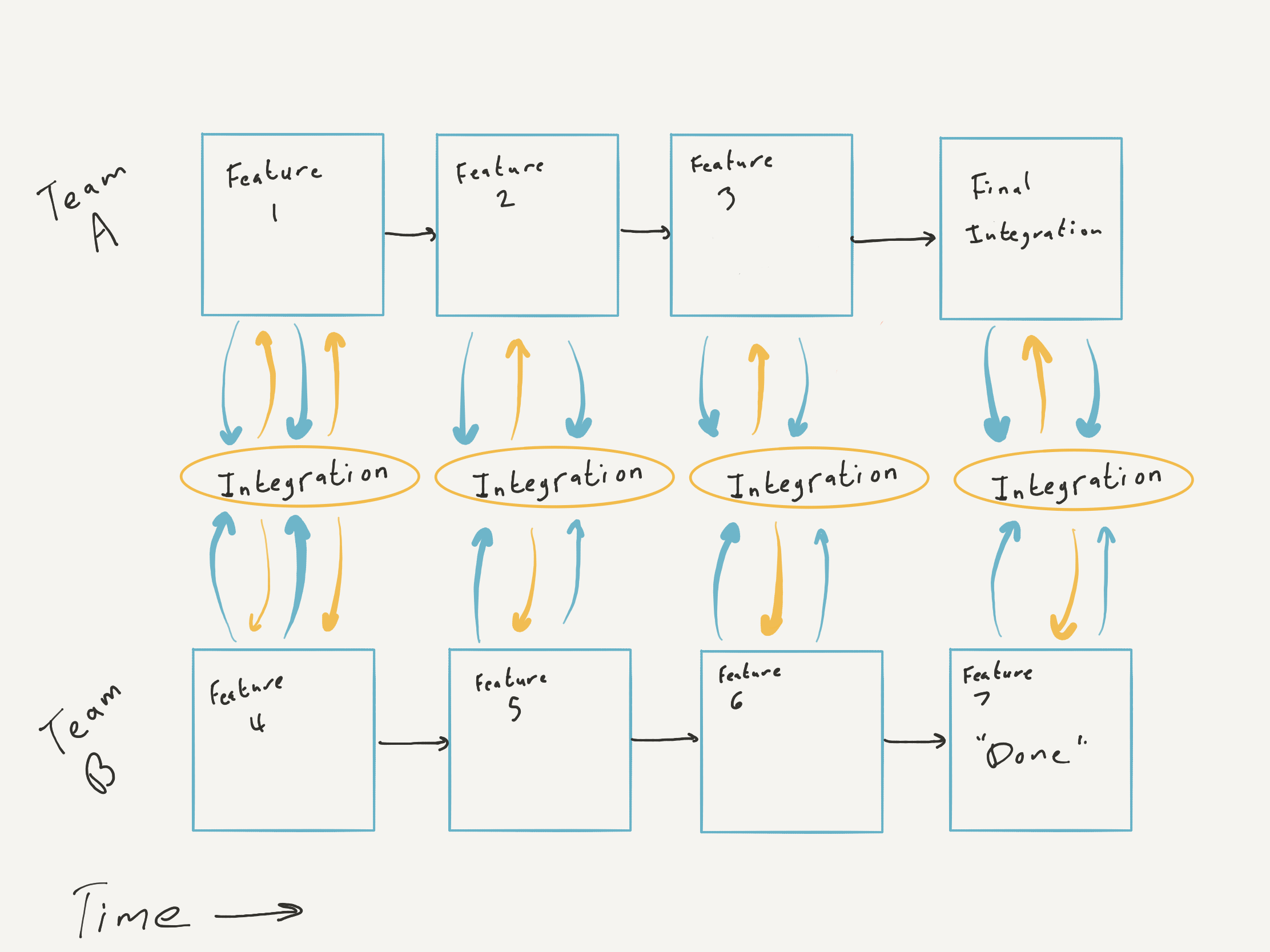
Start testing the app and hardware together as early as possible. It doesn't matter if the hardware looks like a BLE demo kit wire-wrapped to a protoboard or if the only capability is connecting and echoing bytes. Once the system can work together at all, you have a baseline. As parts evolve, you can verify new features work and that nothing has regressed.
Firmware Is Software — Treat It That Way
Despite what I've occasionally heard claimed, firmware and apps are both software. In fact, many organizations refer to firmware as embedded software. That means using the same controls any important software project would use. If anything, the constraints of firmware platforms demand more discipline, not less.
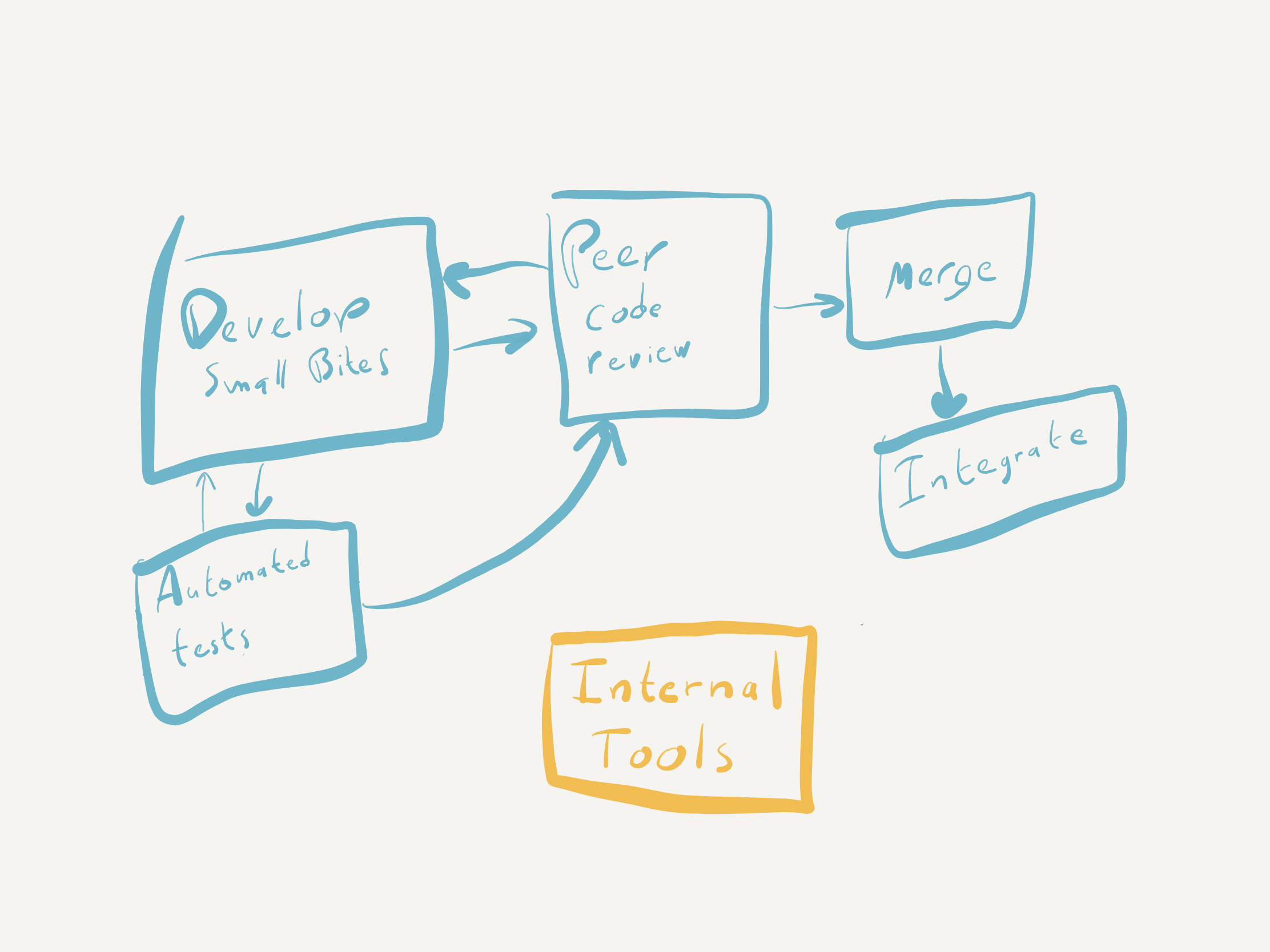
All software goes into version control. The release branch gets locked down, and all changes go through peer code review. I know that sometimes we hire mavericks — intelligent folks who think they don't need code review. Guess what? They still need a code review.
You also need a build server for all software — app and firmware. It should reject any PR with errors, warnings, linter issues, or failed automated tests. A successfully merged PR should trigger a build of release candidates ready for integration testing.
You might worry that setting up a build server will cost you a day or two upfront and an hour a month of maintenance. Fair enough. But an automated build-and-test will save hundreds of hours of pain and suffering. (And that's just counting the debates over indentation.)
The benefits only compound when you start early. Wait too long to add automated tests and linting, and you're compounding technical debt instead. Your team has to catch up on a pile of missed feedback, and they lose the opportunity to make trade-offs between scope and quality.
When you save fixing warnings or static analysis for the last week of the project, it's too late to cut a feature. Cutting features is work. So, however many issues you find, that's the amount of work you have to do — unless you're willing to compromise on quality.
Merge Every Few Days or Pay for It Later
I'll confess: I occasionally bite off more than a week's worth of work in a pull request. Sometimes larger changes are needed, and sometimes I misjudge the scope of a feature.
But aim to merge each working branch back to main within a few days. Teams with long-lived feature branches end up in merge/rebase hell, accidentally regress the codebase, and create cascading rework for everyone else. The more contributors the code has, the worse it gets.
Control over a software project requires small bits of work — easily digested in code review, quickly deployed in an internal release. And then, of course, tested with the whole system.
If you intend to have automated tests, write them alongside the features. Hiring a "unit test person" late in the project rarely adds value. Either everyone writes tests now, or nobody writes tests.
Writing tests after the fact is checking a box without extracting the real benefit. End-of-project test efforts tend to chase coverage goals without finding new bugs. The value of tests is in the feedback loop they create during development — catching regressions as they happen, not documenting them after the fact.
A suite of tests also provides a useful foundation for debugging. When something fails in the field, you can then use your testing platform as a tool to reproduce the same failure signature.
I've seen teams struggle to reproduce and isolate a bug that would have taken minutes to find if they already had a testing framework running. Getting hardware to emit a specific value to trigger a code path is far harder than injecting test values directly. That's reason enough to have the framework in place from day one.
Log Every BLE Interaction — You'll Need It
BLE apps involve multiple execution threads, and Bluetooth peripherals operate asynchronously with the app. The most challenging bugs in BLE systems come from mistakes in asynchronous programming. A robust logging system will save your sanity.
Logs also help reconstruct vague bug reports: "I connected to our BLE thermometer with the app, and it reported a temperature of 0 degrees. But I was standing in the parking lot, and it was closer to 104." A log file might reveal that the calibration value was much higher than expected and the app miscalculated, or that the device had run out of storage for temperature readings and the buffer didn't wrap correctly. The log provides context your app's UI never will.
To start, log every error from Core Bluetooth and the BLE module in the firmware. Log "out of spec" behavior — values outside an enumeration, a default switch case you don't expect to reach.
I've never regretted logging every BLE interaction. When your system does something surprising, BLE logs let you reconstruct the sequence of events that led to it. Without them, you're guessing.
Beyond logging, build simple diagnostic tools into your iOS app. Let internal users view state variables, query values from connected peripherals, run stress tests. The specifics depend on your product, but the principle is the same: give yourself visibility into the system while it's running.
The Short Version
Every iOS + BLE project needs early and frequent integration of the entire system, automated software controls, modern development processes, small units of work, and excellent tools for debugging and monitoring. Start all of these on day one, not the week before launch.
If your team is mid-integration and the connection still drops when someone walks across the room, the BLE & NFC hardware integration practice covers how I help.